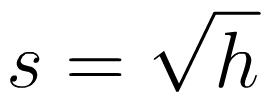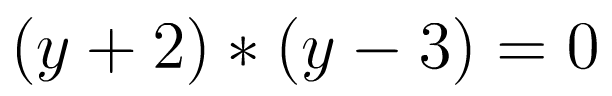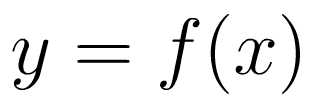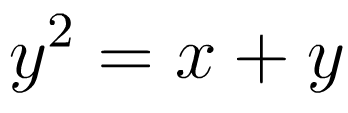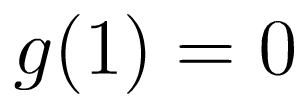A dog came in the kitchen
And stole a crust of bread.
Then cook up with a ladle
And beat him till he was dead.
Then all the dogs came running
And dug the dog a tomb
And wrote upon the tombstone
For the eyes of dogs to come:
'A dog came in the kitchen ...'
-
Waiting for Godot, by Samuel Becket
I have not yet actually read
Waiting for Godot, but my father once sang this song to me when I was very young, and I have never forgotten it. After my initial numbness in response to the cook's shocking violence had subsided, I was overawed by the wisdom and magical prowess of the dogs in this story, who were somehow able to dispense justice by proclaiming the cook's wrongdoing in an epitaph that swallowed the story in which it was introduced, like a snake eating its own tail.
Now, as an adult, I realize that the dogs aren't meant to be real characters in a real story, and that self-similarity in literature is a trope that is not unique to
Waiting for Godot. Nevertheless, because this was my first memorable exposure to self-similarity, I subconsciously associate dogs with recursion, induction, self-similarity, and other related concepts.
Today I'd like to explore how the canine magic of self-similarity can make some simple algebra infinitely more fun. Let's consider the following function:
This function contains infinitely many nested square roots. Functions of this type, although well studied, are rarely encountered in standard mathematics curricula intended to teach practical skills like the foundations of algebra or even more advanced subjects. Nevertheless, they are quite interesting. First, we will consider how to
evaluate this function for a given input. For example, suppose we're given the following:
How can we solve for y?
Next, suppose that we want to find out how to generate a particular output from this function. Can we calculate an inverse for this function? That is, for some variable y, let:
Now, we want to describe some function g such that any x and y that satisfy the above equality also satisfy:
It turns out that we can achieve both of these goals by using a single, fairly simple process of substitution. The key is to realize that in the function f, the whole is
equivalent to its parts. This allows us to perform the following subsitution:
This allows us to easily evaluate the function for a given input:
Actually, since y is equivalent to an expression entirely contained within a square root, y has to be positive. Therefore:
That was fairly straightforward. Using very similar steps, we can invert the function f:
Thus, the following is an inverse of f:
Notice that this makes f an actually useful function in some sense. Normally, if we were told the following:
If we were asked to solve for y, the best we could do would probably be to use the quadratic formula:
However, we can approximate the solution as follows:
We can now easily see that, as long as certain assumptions hold true (for example, x must be greater than zero), the y inside the innermost nested square root becomes less and less significant after repeated substitutions, and this expression approaches our original function f.
Before I finish this post, I would like to add the caveat that the function g described above is not the inverse of f on the real numbers. Rather, f and g are inverse functions only on a specific subset of the real numbers. Whereas the domain and range of f are both restricted to the positive numbers, the domain of g contains the negative numbers. That is, you can plug negative numbers into g and produce a real result, whereas plugging negative numbers into f produces imaginary results, and f can never produce negative results. For example, note the following (double-check by evaluating these for yourself if you want):
Whereas:
This shows in a little more detail exactly what is going on in the evaluation example we did earlier (this is why the specific negative root of -2 showed up in the process of searching for our solution for f(6) even though it was not strictly an acceptable answer).
Slightly more troubling is the fact that f and g are not even inverses on the domain of the positive real numbers, because:
Whereas:
Note that this violates the condition we stipulated earlier that x (the argument to f) must be greater than zero for the inverse relationship to hold, for the nested y does not become less significant with repeated substitutions if x is zero.
In fact, f and g are inverses on the set of positive integers greater than 1. Any such integer can be evaluated by both f and g, and f(g(x)) = x for all positive integers x greater than 1. However, this is not the largest subset of the real numbers on which f and g are inverses. There is some continuous subset of the positive real numbers on which this property holds. Interestingly, I believe that the following is also true on this subset:
However, I am not able to prove this rigorously or precisely delineate the largest subset of the real numbers on which the composition of f and g is the identity relation. I am sure somebody knows the answer, and it's probably on the internet somewhere, but I have yet to find it.
The eyes of dogs are fairly poor because dogs rely far more heavily on olfactory and auditory stimuli than on visual stimuli. Maybe for this kind of problem, it's not how you look at it that matters; maybe you have to sniff out the solution somehow. Right now, my nose just isn't good enough.
UPDATE: After asking around for help, I finally got some great advice from Tony! He pointed out that a function must converge and also be injective in order to be invertible. Note that since the graph of g(x) is a parabola, it clearly fails the vertical line test, and is not injective. To avoid confusion, I should clarify here that in this discussion I am defining g to be the function we described above:
Even though our original motivation for talking about g was finding the inverse of f, I am not defining g to be the inverse of f. Rather, let us define g to be the function above and discuss under what conditions, if any, f is the inverse of this function g.
The portion of g(x) where x is a Real number greater than one is injective and surjective onto the non-negative real numbers, since g(1) = 0 and g(x) is monotonically increasing for inputs greater than 1. That is, the g(x) is an invertible function given the following criteria:
First, g must be restricted to the domain:
This will ensure that g has the following range:
Based on my attempts to plot f(x) in Wolfram Alpha by approximation using a finite number of nestings, f appears to be injective, in fact monotonically increasing, on the nonnegative real numbers. Since we know that:
This means that f is probably surjective onto the nonnegative real numbers. Therefore, f is invertible on a different domain than g.
However, on the domain of Real numbers greater than or equal to 2, I believe that f and g are inverses of each other, because f(2) = g(2) = 2, and both f and g are monotonically increasing on this domain, meaning that they are invertible.
Both f and g are actually invertible on larger domains then this, but in those cases they are not necessarily equal to each other's inverses. For example, it just so happens f(0) = g(0) = 0, but we know that in general g cannot be the inverse of f on the continuous interval [0,2], because g(1) = 0 and f(0) = 0.
Therefore, there must be some other function which is in general the inverse of f on the non-negative real numbers and which is equal to g only on some subset of this domain. Similarly, there must be some function which is in general the inverse of g on the real numbers greater than or equal to 1, but which is only equal to f on some subset of this domain.
I've said "there must be" or "I believe" a lot in this blog, because I've been trying to reconcile graphical approximations from Wolfram Alpha that I used to visualize some of these functions with the properties that I know about functions and some of the more concrete algebra above. I'm not sure how confidently I can draw some of these conclusions, but I think I've settled most of the questions I wanted to answer to my satisfaction - at least, I don't have any intuition about how to proceed more rigorously. This post is definitely pushing the borders of what I actually understand about math.